Your source for product news and developments
New name better reflects our commitment to communicate with you
We're surrounded by moving boxes and construction dust. To better reflect our goal to provide tools and information to keep you, the webmasters, informed and help you increase your crawl coverage and visibility on Google, we're renaming Google Sitemaps to Google webmaster tools. The Sitemaps protocol remains unchanged and Sitemaps submission mechanisms and reporting is still available from the Sitemaps tab. We're also renaming our blog and Google Group to be more broadly focused on webmaster topics.
You can find handy links to all the tools, the new blog, Google Group, help center and more from our newly launched Google webmaster central. Join us at the blog's new location at googlewebmastercentral.blogspot.com where you'll learn about all the exciting things we're planning. Oh, and please don't forget to update your bookmarks and feed!
BlogHer Tips
Yesterday's post was about how BlogHer attendees (and anyone else) can ensure that their web pages get indexed in Google. Here are more tips:
- If you want to keep Google from indexing some pages of your site, you can use a robots.txt file, a simple text file that you place in the root of your site. We provide detailed information about creating a robots.txt file. You can also use the robots.txt analysis tool in Google Sitemaps to make sure that your file blocks and allows the pages you intend.
- If Google has indexed content that you don't want to appear in search results, you have two options:
- If you want to keep the content on your site, you can block that page with a robots.txt file and then request that we remove the page from our index;
- If you remove the content from your site (for instance, you decide that you revealed information that is too personal and you edit your blog post), you can request a cache removal.
- Good content keeps visitors coming back and compels other sites to link to you. In addition to blog posts, you can provide othe types of content, such as video. A number of video hosting sites are available including YouTube, Yahoo! Video, and our very own Google Video. At the conference, some attendees were asking about copyright, and to answer that question, you retain all rights to any content you upload to Google Video.
- If you're interested in running ads on your site, take a look at AdSense. The ads are related to what you're talking about that day on your blog -- and you can control what ads display.
Time to verify
Very soon, we'll be doing one of our periodic checks of verified sites. As our documentation notes, we do this to make sure that the verification HTML file or meta tag still exists. If we don't find the file or tag during this check, the account will no longer show that site as verified, and you'll no longer have access to diagnostics and statistics. If you find that a site that previously verified no longer is, simply click the "Verify" link on the My Sites page and upload the file or meta tag again.
Back from BlogHer
I just got back from BlogHer, a conference primarily for women about the technical and community aspects of blogging. As a woman who blogs, I had a wonderful time. As a woman who blogs about topics of interest to site owners, I gained some new perspectives.
These bloggers tend to already put into practice a lot of the things we tell site owners who ask how to get more of their context indexed and make it easier to find through Google searches. As group, they:
- Provide unique perspectives and content on topics
- Think about their visitors, making sure the sites meet their visitors' needs
- Give visitors reasons to come back, and other sites reasons to link to them (they update content regularly, and most offer in-depth information, such as tutorials, reviews, or in-depth explanations).
Given all of the dedication these bloggers put into their sites, they are of course interested in attracting visitors. Some want the joy of sharing; others are interested in making money from their writing. Here are a few tips to help make your site easier to find, whatever your motivation:
1) High-quality links from other sites help bring visitors to your site and can help your site get indexed and well-ranked in Google. The number one question asked at this conference was "What is your site?" People want to know so they can go read it, and if they like it, link to it. But the number one answer to this question was the name of the site, not the URL. Bloggers had T-shirts of their sites available, and many of those didn't have URLs. Tell people your URL so they can find you, read you, and link to you!
2) Make sure Google can crawl your site. We use an automated system (called "Googlebot") to visit pages on the web, determine their contents, and index them. Sometimes, Googlebot isn't able to view pages of a site, and therefore can't index those pages. There are two primary things you can do to check your site.
a. Read our webmaster guidelines to learn about how we crawl sites and what can make that easier.
b. Sign up for a Google Sitemaps account to see a list of errors we encountered when we tried to crawl your site. This way you can find out if we can't reach your site, and why. Once you sign up for a Google Sitemaps account and add your site URL, you need to verify site ownership before you can see diagnostic information. To do this, simply click the Verify link and follow the steps outlined on the Verify page.
You can verify site ownership in one of two ways:
- Upload an HTML file with a specific name to your site
- Add a <meta> tag to your site's home page
You can also see what words other sites use to link to you (which helps explain why your site might show up for searches that you think are unrelated to your site).
3) Submit an RSS feed of your site to quickly tell us about all of your pages, so we know to crawl and index them.
Support for Polish
Google Sitemaps has added support for Polish. If you already use Google in Polish, you should see the Sitemaps user interface in Polish automatically. Otherwise, you can click the Preferences link from the Google home page and choose Polish from the interface list.
The webmaster help center is also now available in Polish. This includes all the content in the help center, including our webmaster guidelines. Simply choose "Polish" from the Change Language menu. We also have a Polish Google Group for discussing Sitemaps and other webmaster issues.
More control over titles too
Yesterday we told you that you can use a meta tag to ask us not to use descriptions of your site from the Open Directory Project (ODP) when we generate snippets. Some of you have asked if this meta tag prevents us from using the title from the ODP as well. Yes, this meta tag does apply to both the title and description from the ODP.
Also, as noted in our webmaster help center, you can combine parameters in the meta tag. So, for instance, you could use the following meta tag:
<meta="robots" content="noodp, noarchive">
More control over page snippets
The way we generate the descriptions (snippets) that appear under a page in the search results is completely automated. The process uses both the content on a page as well as references to it that appear on other sites.
One source we use to generate snippets is the Open Directory Project, or ODP. Some site owners want to be to able to request not using the ODP for generating snippets, and we're happy to let you all know we've added support for this. All you have to do is add a meta tag to your pages.
To direct all search engines that support the meta tag not to use ODP information for the page's description, use the following:
<META NAME="ROBOTS" CONTENT="NOODP">
Note that not all search engines may support this meta tag, so check with each for more information.
To direct Google specifically from using this information to describe a page, use the following:
<META NAME="GOOGLEBOT" CONTENT="NOODP">
For more information, visit the webmaster help center.
Once you add this meta tag to your pages, it may take some time for changes to your snippets to appear. Once we've recrawled your pages and refreshed our index, you should see updated snippets.
Tips for Non-U.S. Sites
If you're planning to be at Search Engine Strategies Miami next Monday and Tuesday, stop by and say hi at the Google booth. I'll be there answering any questions you may have about Sitemaps. This event is all about the Latin American market, so here's some information you might find helpful if your site is in Latin America or elsewhere.
If you want your site to show up for country-restricted searches, make sure it uses a country-specific domain (such as www.example.com.br). If you use a domain that isn't country specific (such as .com), make sure that the IP address of the site is located in that country.
If you want to know what visitors from different countries are searching for, take a look at the query stats in Sitemaps. This lets you see the difference in searches for each location, as well as what languages visitors use to type in their queries.
Get more from the latest release
In response to your requests, our latest release expands some of the features of Google Sitemaps. Here’s a roundup of what’s new.
Increased crawl errors
Previously, we showed you up to 10 URLs for each error type. We now show all URLs we’ve had trouble crawling. We’ve also put 404 (not found) errors in a separate table from other HTTP errors.
Just choose an error type and either browse the table using the Next and Previous links or download the entire table as a CSV file.
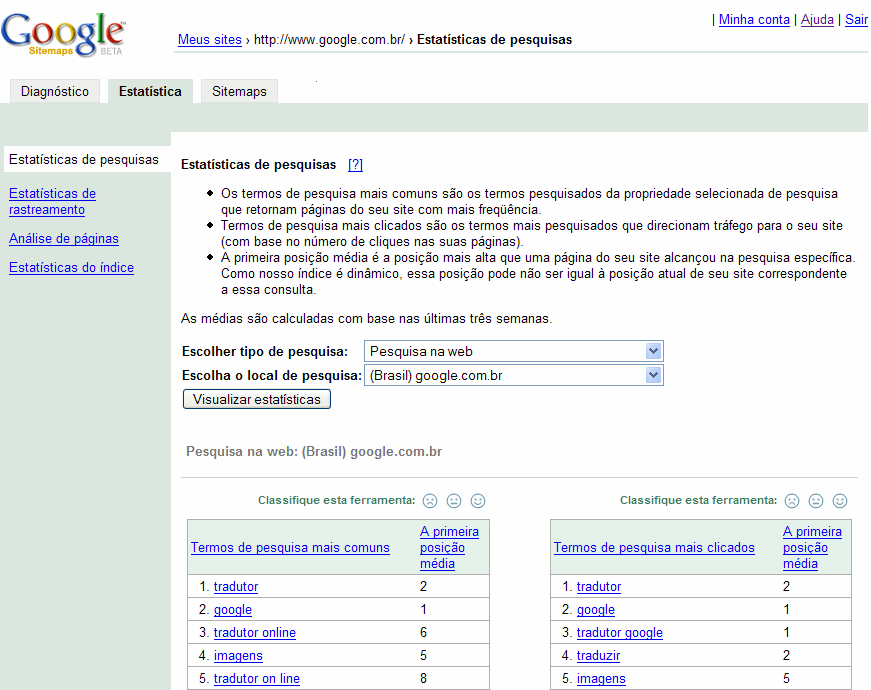
 Expanded query stats
Expanded query statsQuery stats show you the top 20 search queries that brought up your site in the Google search results (both when users clicked on your site in the results and when they didn’t), along with the average top position of your site for that query. Previously, you could view aggregate data across all properties and countries, as well as mobile-specific queries.
Now, you can view data for individual properties and countries as well. For instance, you can see the search queries from users searching Google Images in Germany that returned your site in the results. You’ll only see properties and countries for which your site has data.
Site owners can also view aggregate information for all properties and languages. Properties include Images, Froogle, Groups, Blog search, Base, and Local. More than 100 countries are available.
Previously, query stats were available for sites that were located at the top-level domain (for instance, http://www.example.com/). These stats are now also available for sites located in a subfolder (for instance, http://www.example.com/mysite/).

Increased number of common words
On the Page analysis page, we’ve expanded the list of words we show in the report of common words on your site and in external links to your site from 20 to 75 and we've removed http and www from the words we list.
Increased limit of sites and Sitemaps that can be added to an account
In response to requests, we’ve raised the number of sites and Sitemaps that site owners can add to a Google Sitemaps account from 200 to 500 — a direct result of a request from a Google Group member.
robots.txt analysis tool addition
Our robots.txt analysis tool is a great way to ensure that the robots.txt file on the site blocks and allows only what’s intended. We’ve added the ability to test against the new Adsbot-Google user agent, which crawls AdWords landing pages for quality evaluation. We only use this bot if you use Google AdWords to advertise your site. You can find out more about this user agent in the AdWords help center.
We want to know what you think
We are constantly looking to improve Google Sitemaps and appreciate the feedback we get from our Google Group, other places online, and at conferences. But we know that we don’t get to hear from everyone that way. And so, to gather more feedback, we’ve added a rating tool to each feature in Sitemaps. Tell us if you love the feature, would like us to improve it, or if you don’t find it useful. Simply click your choice beside each feature.

Webmaster help center updates
We recently updated our webmaster help center . Two new sections that you may find particularly useful are:
- Using a robots.txt file
- Understanding HTTP status codes
We've added a new section of help topics in the How Google crawls my site section. These topics include information on:
- How to create a robots.txt file
- Descriptions of each user-agent that Google uses
- How to use pattern matching
- How often we recrawl your robots.txt file (around once a day)
This section explains HTTP status codes that your server might return when we request a page of your site. We display HTTP status codes in several places in Google Sitemaps (such as on the robots.txt analysis page and on the crawl errors page) and some site owners have asked us to provide more information about what these mean.
The Sitemaps Google Group
If you use Sitemaps, you should check our our Google Group. The Sitemaps team monitors this community to learn about any issues Sitemaps regulars may be having, as well as about feature requests and suggestions for enhancements. In addition, the members are great about helping each other out. If you do post a question or issue to the Group, please include your site URL (and Sitemap URL if your question is about a Sitemap) and any error message you received. This enables other Group members to help you more quickly and helps the Sitemaps team troubleshoot issues. We greatly appreciate the Group discussions and use the feedback to make Sitemaps better.
Thanks for your participation and input!
Another update on the site: operator
We've fixed the issue with the trailing slash in site: operator queries. Queries for site:www.example.com and site:www.example.com/ should now return the same set of results.
An update on the site: operator
We've fixed the issue with site: queries for domains with punctuation in them. We are still working on site: operator queries for domains that include a trailing slash at the end (such as site:www.example.com/ ), so you may get better results for now by omitting the trailing slash in your queries. The Index Stats page of Google Sitemaps no longer uses the trailing slash for its queries, so you should see correct results when using this page.
Thanks for your feedback and patience.
Live in our hometown
We had a great time at Search Engine Watch Live Seattle last week, answering questions and getting feedback. We even got to meet one of our Google Group members! We wanted to share some of the questions we answered for those who couldn't be there.
When I do a link: search, the results don't include all the links to my site. How can I tell you about the other links?
A search using the link: operator returns only a sampling of pages that link to a site. It doesn't include the full list we know about. We find links to your site through our regular crawling mechanisms, so there's no need to tell us separately. Keep in mind that our algorithms can distinguish natural links from unnatural links.
Natural links are links to your site that develop as part of the dynamic nature of the web when other sites find your content valuable and think it would be helpful for their visitors. Unnatural links are links to your site placed there specifically to make your site look more popular to search engines. Some of these types of links are covered in our webmaster guidelines:
- Don't participate in link schemes designed to increase your site's ranking or PageRank. In particular, avoid links to web spammers or "bad neighborhoods" on the web, as your own ranking may be affected adversely by those links.
- Avoid "doorway" pages created just for search engines.
In general, linking to web spammers and "bad neighborhoods" can harm your site's indexing and ranking. And while links from these sites won't harm your site, they won't help your indexing or ranking. Only natural links add value and are helpful for indexing and ranking your site.
My site participates in an affiliate program. What tips can you provide?
Google's goal is to provide relevant and useful results to searchers. Make sure that your site provides unique content that adds value beyond an affiliate link or the content provided as part of the program. We talk about this in our webmaster guidelines as well:
- Avoid "cookie cutter" approaches such as affiliate programs with little or no original content.
- If your site participates in an affiliate program, make sure that your site adds value. Provide unique and relevant content that gives users a reason to visit your site first.
Look at your site and determine what you can offer that will make searchers want to visit and what can distinguish it from other sites in the same affiliate program. And while we expanded on the information in our guidelines specifically because so many people asked us about their affiliate sites, this information is true for all sites. If there's no added value to users, then it's unlikely that search engines will find added value either.
A few questions from our Google Group
In this post, we thought we'd answer a couple of the questions we've been seeing in the Google Group lately.
Why do I have to add my Sitemap file to my Google Sitemaps account? Can't I just link to it from my site?
There are several reasons we ask you to add the Sitemap file. Here are a couple of them:
- If you aren't yet indexed, submitting a Sitemap file lets us know about your site--you can proactively tell us about it rather than wait for us to find it.
- When you add your Sitemap file to your Google Sitemaps account, we can let you know if the file has any errors, and then you can resubmit the file once you've fixed the errors.
This can happen when both versions of the domain (for instance, http://www.example.com/ and http://example.com/) point to the same physical location, and links to your site use both versions of the URL. To tell us which version you want the content indexed under, we recommend you do a 301 redirect from one version to the other. If your site runs on an Apache server, you can do this using an .htaccess file. You can also use a script. Do a Google search for [301 redirect] for more information on how to set this up for your site. Note that once you implement the 301 redirect, it may take some time for Googlebot to recrawl the pages, follow the redirects, and adjust the index.
If your pages are listed under both versions of the domain, don't use our URL removal tool to remove one version of the pages. Since the pages are at the same physical location for both versions of the domain, using the URL removal tool will remove both versions from the index.
We also suggest you link to other pages of your site using absolute, rather than relative, links with the version of the domain you want to be indexed under. For instance, from your home page, rather than link to products.html, link to http://www.example.com/products.html . And whenever possible, make sure that other sites are linking to you using the version of the domain name that you prefer.
Issues with the site: operator query
We'd like to give you all a quick update on some of the issues you have been seeing when you do a site: search to see how many pages of your site are in the index. We've been refreshing our supplemental results (you can read more about that in Matt Cutts' blog post) and this refresh has involved some serious changes under the hood. Unfortunately, with change of this scale, there sometimes are bugs. In this case, we found a few bugs that affected the site: operator. Some particular ones you may have noticed are that the following types of queries don't return the correct number of results:
- site: queries where you type in a trailing slash (such as site:www.example.com/)
- site: queries for a domain with punctuation (such as site: www.example-site.com)
We've got fixes for all of these rolling out in the next few days. They didn't come out sooner because we've been testing them thoroughly, making sure you don't get any unexpected surprises.
This bug doesn't involve any pages being dropped from the index. It's the site: operator that isn't working properly. We're freezing all refreshes of the supplemental results until these issues are fixed, and things should be back to normal in a few days. We'll keep you posted when all fixes have been made.
In the meantime, site: queries without the trailing slash may provide a better result (such as site:www.example.com). If you are checking your site using the Index Stats page of Google Sitemaps, note that it uses the trailing slash in the query, so you may see incorrect results until this bug is fixed.
Thanks for your patience as we resolve this issue.
https verification
Recently, we told you that we were working on making verification of site ownership available for https sites. This is now available, so if you have an https site, you can now verify site ownership and see statistics and diagnostic information.
More about meta tag verification
As we mentioned last week, we've added a new option for verifying site ownership. This method requires that you place a specific <meta> tag in the source code of your home page. Many features are available only to site owners and we want as many webmasters as possible to have access. Most site owners who can't upload files or specify names for files should be able to use this new method to verify. For instance, if you use Blogger, you can verify using this option.
To verify using the <meta> tag, simply click the Verify link for your site, choose Add a meta tag as the verification option, and then copy the tag provided to the <head> section of your home page.
This tag looks like this:
<meta name="verify-v1" content="unique-string">You must place this meta tag:
- On the home page of your site (sometimes called the index page or root page).
- In the source code for that page.
- In the first <head> section of the page, before the first <body> section.
For instance, this is correct:
<html>The meta tag inside the style section is incorrect:
<head>
<meta name="verify-v1" content="unique-string">
<title>Title</title>
<style>
<!-- style info here -->
</style>
</head>
<body>
<!-- body of the page here -->
</body>
</html>
<head>The meta tag inside the body section is incorrect:
<title>Title</title>
<style>
<meta name="verify-v1" content="unique-string">
</style>
</head>
<body>
...
<html>The meta tag on a page with no head section is incorrect:
<head>
<title>title</title>
</head>
<body>
<meta name="verify-v1" content="unique-string">
</body>
</html>
</html>Below are some questions you might have about verification.
<meta name="verify-v1" content="unique-string">
...
<html>
I have a blog, and anyone can post comments. If they post this meta tag int a comment, can they can claim ownership of my site?
No. We look for this meta tag in the home page of your site, only in the first section and before the first . If your home page is editable (for instance, your site is a wiki-like site or a blog with comments or has a guest book), someone can add this meta tag to the editable section of your page, but cannot claim that they own it.
So, how do you generate these cryptic tags anyway?
The unique string is generated by base-64 encoding the SHA256 hash of a string that is composed of the email address of the proposed owner of the site (for instance, admin@example.com) and the domain name of the site (for instance, example.com).
From this unique string, can someone determine my email address or identity?
Short answer, no. Long answer, we use a hashing scheme to compute the contents of the meta tag. Hashes cannot be "decrypted" back into the message.
Can the meta tag contents be cracked through a dictionary attack?
To reduce the risk of dictionary attacks, we use a random sequence of bytes (called salt) as a seed to the hash function. This makes dictionary attacks much more difficult.
Can someone determine if the same webmaster own multiple sites?
We use the domain name of your site (for instance, example.com ) to compute the unique string. Based on the contents of the tag, someone can determine if a webmaster owns different sites on the same domain, but not if the webmaster owns sites on different domains. For instance, someone can determine if the same webmaster owns http://www.example.com/ and http://subdomain.example.com/, but can't determine if the same webmaster owns http://www.example.com/ and http://www.google.com/.
What if my home page is not HTML content?
This method may not work for you. You must have a <head> section in order to be able to verify using this approach. Instead, try uploading a verification file to verify ownership of your site.
I've added my tag, but Google Sitemaps says it couldn't find it. Why?
Make sure your tag is in the first <head> section, and before the <body> section. Also ensure that it's not within the <style> tags or other specialized tags. The easiest way to make sure that the placement is one we can recognize is placing it right after your opening <head> tag, as follows:
<head>
<meta name="verify-v1" content="unique-string">
Updated robots.txt status
Thanks to our users for alerting us to an issue with incorrectly reporting that sites and Sitemaps were being blocked by robots.txt files. We have resolved this issue. If you were unable to add a site or Sitemap because of this issue, you should now be able to add them.
If Sitemaps was reporting that your home page was blocked by robots.txt, you should soon see an updated status. Thanks for your patience as we refresh the display of this data.
If we were incorrectly reporting that your robots.txt file was blocking your Sitemap, you will see an updated status the next time we download your Sitemap.
Thanks as always for your valuable feedback.
A whole new look and a lot more
If you log in to Sitemaps today, you'll notice some changes. We've revamped the interface based on your feedback to make your account easier to use. There's more below on the facelift, but first, here are details about the new features we've added.
Since the Google Sitemaps program is built on the idea of two-way communication between Google and webmasters we hope this update gives you as much information as possible to help you debug your site and help ensure it is crawled and indexed as effectively as possible.
New verification method
Many features of Sitemaps are available only to site owners. Some of you aren't able to use our existing verification method, so we asked for your feedback on an alternate method of verification that uses a meta tag on the root page of your site. The response was overwhelmingly positive, so we've added this method as an option.
To verify ownership of your site using this method, simply click the Verify link for your site, choose Add a META tag as the verification option, and then copy the tag provided to the <head> section of your home page. Once you've done that, select the checkbox and click Verify. We'll post something soon with more details about this.
Indexing snapshot
The new Summary page provides a quick snapshot about the state of your site, including:
- If site is in the index
- When Googlebot last accessed the home page
- If some pages of the site are partially indexed
- If the home page is currently inaccessible
- If Googlebot has encountered a large number of errors when trying to crawl the site
 Notification of violations of the webmaster guidelines
Notification of violations of the webmaster guidelinesWe may use the summary page to tell you if a site has violated the webmaster guidelines so you can correct the problems and request reinclusion.

Reinclusion request form
The reinclusion request form is available once you sign in to Sitemaps. Simply sign in, click the link, and fill out the form. This form is also available from the Summary page for sites that show violations. Remember, if your site hasn't violated the webmaster guidelines, there's no need to submit a reinclusion request.
Spam report
The spam report form is available once you sign in to Sitemaps. This form is already available outside of Sitemaps, but we wanted to make it available inside as well for two reasons: so that all tools you need for the Google index are available in one place, and because reports that come from within Sitemaps are from users who are signed in, so your report may receive more in-depth consideration.
New webmaster help center
We've launched a new help center for webmasters as a central place for comprehensive information. It includes the webmaster guidelines and details on Googlebot, crawling, indexing, and ranking--plus information about using Sitemaps. It includes all of the information that was previously located at www.google.com/webmasters, as well as much of the information that was located in the Sitemaps documentation. Over time, we'll be adding more information to the help center to answer any questions you might have.
Throughout your Sitemaps account, you'll notice a [?] link in places where additional information is available. Simply click the link to access the help center.
More about our new look
We want Google Sitemaps to be easy to use for everyone. You may notice that a few things have moved around. For instance:
Adding a Sitemap
To add a Sitemap, first add the site. Then, click the Add a Sitemap link beside the site on the My Sites page. To add more Sitemaps for that site, just access the Sitemaps tab for the site and click Add a Sitemap there.
Navigating the tabs
You'll notice that the tabs have changed a bit. When you access a site, you'll see the Summary page of the Diagnostic tab. All the information that used to be under the Errors tab and the robots.txt tab is available from the Diagnostic tab as well. The Statistics tab contains all the pages that were under the Stats tab and the Sitemaps tab has remained the same. You won't see a Verify tab, but the Verify link is available from the My Sites page and the Diagnostic and Statistics tabs.
Back from Pubcon
We had a great time meeting with webmasters and talking about Sitemaps at Pubcon in Boston. We value feedback and suggestions, and appreciate our Google Group posters. But it's great to be able to talk to webmasters in person too. For those of you who couldn't be there for in-person conversation, here's a recap of the top three questions we were asked.
What's the best way to go about changing domain names?
We've done two blog posts about this that you might find helpful:
Do you have any advice for using a robots.txt file?
We have lots of advice! And if you are thinking of creating a robots.txt file for your site or modifying your existing one, be sure to check out the Sitemaps robots.txt analysis tool so you can test how Googlebot will see your file.
Can you look at my site and tell me how to get better ranking and indexing?
I sat in on the Organic Site Reviews panel, where the panelists were giving out lots of great advice about this. Check out my guest post in Matt Cutts' blog for the highlights.
Thanks to everyone who came up to say hello. And thanks for all the great questions and feedback.
Join us for lunch!
If you're planning to be at PubCon in Boston this week, join us for lunch with Googlers on Tuesday at 12:50. We'll be talking about how to get the most from your Sitemaps account and answering your questions. Hope to see you there!
More third-party tools
We've just updated our list of third-party tools that support Sitemaps. Check it out if you're looking to create a Sitemap.
We appreciate the support of the Sitemaps community and all the hard work that has gone into development of these tools.
Using the lastmod attribute
With our recent infrastructure changes, we've made some minor changes in how we process the lastmod attribute. If you omit the time portion, it defaults to midnight UTC (00:00:00Z). If you specify a time, but omit the timezone, you'll get an invalid date error. You'll also get an invalid date error if you specify an invalid date or time (like February 80th) or the date isn't in the correct format. You'll no longer see errors associated with future dates.
Dates must use W3C Datetime encoding, although you can omit the time portion. For instance, the following are both valid:
- 2005-02-21
- 2005-02-21T18:00:15+00:00
https verification
Some of you have had trouble verifying ownership of https sites (for instance, https://www.example.com/). We are working on this issue and will have it resolved as quickly as possible. We'll let you know as soon as you are able to verify https sites.
Resolving issues listed in the Errors tab
Another question from our mailbag:
Q: Under the Errors tab, I see a URL listed with a 404 error. That page doesn't exist on my site and I don't link to it. Why does this show up?
A: The Errors tab lists both errors we encountered following links in your Sitemap and errors we had following links during our regular discovery crawl. If we tried to follow the link from the Sitemap, the URL lists "Sitemap" beside it. If it doesn't list "Sitemap", then we tried to follow that link from a web page (either on your site or another site). You might double-check your site and make sure that none of the internal links are pointing to that URL. If they aren't, then this URL is probably linked from an external page.
Adding new content
This week, we thought we'd answer some of the questions we've gotten recently. If you have questions, just head on over to our Google Group. The group members are really helpful and we'll answer questions here as we can.
Q: I'm adding a new section to my site, which will add quite a bit of content. Should I create a Sitemap with all of my content and submit that, or should I create several Sitemaps and submit them over a period of a few weeks?
A: A single Sitemap and multiple Sitemaps are handled in exactly the same way, so it really comes down to what's easiest for you. If you have fewer than 50,000 URLs, you can simply create one Sitemap with everything in it and submit that. You could also create a separate Sitemap with the new content if that is easier for your to manage. However, you don't need to stagger the submission dates. Whether you choose to create one Sitemap or multiple Sitemaps, you can submit all your pages at one time.
Robots.txt tab maintenance
Today, we'll be performing maintenance on the infrastructure that displays the information for the robots.txt tab. During this time, you may see a status of "Not found" for your robots.txt file. This maintenance affects only the display of the information, and will not impact Googlebot's processing of your file. Googlebot will continue to read and follow your file correctly during this maintenance period.
We will finish this maintenance as quickly as possible and you should see the correct display of data on the robots.txt tab later today. Thanks for your patience.
More information on the new "unsupported file format" error for Sitemaps
As we told you a couple of days ago, we've recently enhanced the infrastructure that processes Sitemaps. We've begun processing Sitemaps against stricter guidelines because we are committed to interoperability with other tools that are using this protocol. Because of this, some of you now see an "unsupported file format" error for Sitemaps that previously had an "OK" status.
You'll see this error if the parser doesn't recognize a valid Sitemap file. Here are a few things to check if you see this error:
- Confirm that the file uses the correct header. For a Sitemap file, the header can look like this:
<?xml version="1.0" encoding="UTF-8"?>
For a Sitemap index file, the header can look like this:
<urlset xmlns="http://www.google.com/schemas/sitemap/0.84"><?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.google.com/schemas/sitemap/0.84"> - Ensure the namespace in the header is "http://www.google.com/schemas/sitemap/0.84". Note that this must end in 0.84. If it ends in .84, you'll see an error.
- Make sure each XML attribute is enclosed in either single quotes (') or double quotes (") and that those quotes are straight, not curly. If you use a word processing program, such as Microsoft Word, you may find that it inserts curly quotes.
Improving things behind the scenes
We've just made some enhancements to the infrastructure that processes Sitemaps. You shouldn't notice many changes, although you may see new and more detailed error messages for your Sitemaps. If you see a different error message than you've seen before, you can click on it to view more information about it.
This change may cause some Sitemaps that used to have a status of OK to display an error message. This is because we've enhanced our reporting to provide error information that wasn't available to you before. For instance, if you see an "Invalid file format" error, make sure that you've declared the namespace in your Sitemap file correctly and that the header matches the examples we provide in our documentation.
As part of this change, you can no longer list Sitemap index files within Sitemap index files. Each Sitemap index file can list only Sitemaps. Remember that you can list up to 1,000 Sitemaps in each Sitemap index file. If you have more than 1,000 Sitemaps for a site, you can submit multiple Sitemap index files.
We've also changed the verification error message we talked about in a recent blog post. If you request verification and we receive a status other than 200 or 404 when we try to access a non-existent file on your site, you'll now see an "HTTP error".
We expect this change to be a smooth one, but please let us know in our Google Group if you experience any trouble.
If you see a "we couldn't find your verification file" error when you try to verify
When you verify site ownership, we check to see if the verification file exists on your webserver. We also make sure that your server returns a status of 404 (not found) when we request a file that doesn't exist. We do this to make sure that when we check to see if the verification file exists, we're getting the right response because it does exist and not because the server is misconfigured.
Some of you have gotten the following message when trying to verify your site: "We couldn't find your verification file. Make sure it is named correctly and is uploaded to the correct location." But when you check the file in a browser, it does exist.
We have looked into this and have found that we are displaying the incorrect error message. What is actually happening in this case is that when we request a file that doesn't exist, we are getting a response other than 404 or 200. (If we get a response of 200, we display a different error message.)
We are working to display the correct response for these cases. In the meantime, if you see this message when you try to verify and your verification does exist in the correct location, check your webserver configuration and make sure that it returns a status of 404 when a request is made for a non-existent page.
We've fixed an issue with verification files that included leading zeros
Thank you to our Google Group members for finding a bug in the verification file logic, which stripped out leading zeros when we accessed the verification file. We've fixed this. This should have only affected site owners with verification files that had the pattern google0<unique_string>.html. If your verification file has this pattern and you've had trouble verifiying, please request verification again.
More new features
We've just released a few new features.
Query stats: average top position
We already show you the top search queries that both returned your site in the results and those that searchers clicked on. Now you can see the top position for your site in the search results for both sets of queries. This position is the average over the last three weeks.
Top mobile search queries
We now also show you the top search queries from mobile devices that returned your site in the results. You'll see both mobile searches of all sites , and mobile searches of mobile-specific sites. You'll only see these results if they are available for your site. Note that at this time, we show only top search queries and not the clicks for those queries.
Downloading Sitemap details, stats, and errors
You can now download information from your Sitemaps account to a comma separated value file, which you can open in any text editor or spreadsheet program. Download this information per table, or download Sitemap details, errors, or stats, for all sites in your account in one file.
Come by and say hi
This week, some of the Sitemaps team will be at Search Engine Strategies NYC. If you're planning to be there on Monday, come have lunch with us and Matt Cutts. We'll be around throughout the conference and we'd love to talk to you. Please come over and say hi if you see us.
Also, last week, I talked all things Sitemaps with GoodROI on his show GoodKarma. Check out the podcast on Webmaster Radio.
Using a robots.txt file
A couple of weeks ago, we launched a robots.txt analysis tool. This tool gives you information about how Googlebot interprets your robots.txt file. You can read more about the robots.txt Robots Exclusion Standard, but we thought we'd answer some common questions here.
What is a robots.txt file?
A robots.txt file provides restrictions to search engine robots (known as "bots") that crawl the web. These bots are automated, and before they access pages of a site, they check to see if a robots.txt file exists that prevents them from accessing certain pages.
Does my site need a robots.txt file?
Only if your site includes content that you don't want search engines to index. If you want search engines to index everything in your site, you don't need a robots.txt file (not even an empty one).
Where should the robots.txt file be located?
The robots.txt file must reside in the root of the domain. A robots.txt file located in a subdirectory isn't valid, as bots only check for this file in the root of the domain. For instance, http://www.example.com/robots.txt is a valid location. But, http://www.example.com/mysite/robots.txt is not. If you
don't have access to the root of a domain, you can restrict access using the Robots META tag.
How do I create a robots.txt file?
You can create this file in any text editor. It should be an ASCII-encoded text file, not an HTML file. The filename should be lowercase.
What should the syntax of my robots.txt file be?
The simplest robots.txt file uses two rules:
- User-Agent: the robot the following rule applies to
- Disallow: the pages you want to block
These two lines are considered a single entry in the file. You can include as many entries as you want. You can include multiple Disallow lines in one entry.>
User-Agent
A user-agent is a specific search engine robot. The Web Robots Database lists many common bots. You can set an entry to apply to a specific bot (by listing the name) or you can set it to apply to all bots (by listing an asterisk). An entry that applies to all bots looks like this:
User-Agent: *
Disallow
The Disallow line lists the pages you want to block. You can list a specific URL or a pattern. The entry should begin with a forward slash (/).
- To block the entire site, use a forward slash.
Disallow: /
- To block a directory, follow the directory name with a forward slash.
Disallow: /private_directory/
- To block a page, list the page.
Disallow: /private_file.html
URLs are case-sensitive. For instance, Disallow: /private_file.html would block http://www.example.com/private_file.html, but would allow http://www.example.com/Private_File.html.
How do I block Googlebot?
Google uses several user-agents. You can block access to any of them by including the bot name on the User-Agent line of an entry.
- Googlebot: crawl pages from our web index
- Googlebot-Mobile: crawls pages for our mobile index
- Googlebot-Image: crawls pages for our image index
- Mediapartners-Google: crawls pages to determine AdSense content (used only if you show AdSense ads on your site).
Can I allow pages?
Yes, Googlebot recognizes an extension to the robots.txt standard called Allow. This extension may not be recognized by all other search engine bots, so check with other search engines you're interested in to find out. The Allow line works exactly like the Disallow line. Simply list a directory or page you want to allow.
You may want to use Disallow and Allow together. For instance, to block access to all pages in a subdirectory except one, you could use the following entries:
User-Agent: Googlebot
Disallow: /folder1/
User-Agent: Googlebot
Allow: /folder1/myfile.html
Those entries would block all pages inside the folder1 directory except for myfile.html.
I don't want certain pages of my site to be indexed, but I want to show AdSense ads on those pages. Can I do that?
Yes, you can Disallow all bots other than Mediapartners-Google from those pages. This keeps the pages from being indexed, but lets Googlebot-MediaPartners bot analyze the pages to determine the ads to show. Googlebot-MediaPartners bot doesn't share pages
with the other Google user-agents. For instance, you could use the following entries:a
User-Agent: *
Disallow: /folder1/
User-Agent: MediaPartners-Google
Allow: /folder1/
I don't want to list every file that I want to block. Can I use pattern matching?
Yes, Googlebot interprets some pattern matching. This is an extension of the standard, so not all bots may follow it.
Matching a sequence of characters
You can use an asterisk (*) to match a sequence of characters. For instance, to block access to all subdirectories that begin with private, you could use the following entry:
User-Agent: Googlebot
Disallow: /private*/
How can I make sure that my file blocks and allows what I want it to?
You can use our robots.txt analysis tool to:
- Check specific URLs to see if your robots.txt file allows or blocks them.
- See if Googlebot had trouble parsing any lines in your robots.txt file.
- Test changes to your robots.txt file.
Also, if you don't currently use a robots.txt file, you can create one and then test it with the tool before you upload it to your site.
If I change my robots.txt file or upload a new one, how soon will it take affect?
We generally download robots.txt files about once a day. You can see the last time we downloaded your file by accessing the robots.txt tab in your Sitemaps account and checking the Last downloaded date and time.
We'd like your feedback on a potential new verification process
Before we show you site stats, we verify site ownership by asking you to upload a uniquely named file. Some webmasters can't do this (for instance, they can't upload files or they can't choose filenames). We are considering adding an alternate verification option and would like your feedback. This option would be an additional choice. It would not replace the current verification process. If you have already verified your site, you won't need to do anything new.
This alternate verification process would require that you place a META tag in the <HEAD> section of your home page. This META tag would contain a text string unique to your Sitemaps account and site. We would provide you with this tag, which would look something like this:
<meta name="owner-v1" contents="unique_string">
We would check for this META tag in the first <HEAD> section of the page, before the first <BODY> section. We would do this so that if your home page is editable (for instance, is a wiki-type page or a blog with comments), someone could not add this META tag to the editable section of your page and claim ownership of your site.
The unique string would be a base-64 encoded SHA-256 hash of a string that is composed of the email address of the owner of the site (for instance, admin@google.com) and the domain name of the site (for instance, google.com).
We'd like your comments on this proposal. For those of you who can't verify now, would this be a method you could use to verify? Do you see any potential problems with this method? Let us know what you think in our Google Group.
We've fixed a few things
We've just fixed a few issues that our Google Group members brought to our attention.
Capitalization in robots.txt lines
Our robots.txt analysis tool didn't correctly interpret lines that include capitalized letters. This has been fixed. All results with URLs that include capital letters are being processed correctly. Note that in a robots.txt file, the capitalization of the rules don't matter. For instance, Disallow: and disallow: are interpreted in the same way. However, capitalization of URLs does matter. So, for the following robots.txt file:
User-agent: *http://www.example.com/Myfile.html is blocked. But http://www.example.com/myfile.html is not blocked.
Disallow: /Myfile.html
Google User-agents other than Googlebot
Our robots.txt analysis tool didn't correctly process robots.txt files for Google user-agents other than Googlebot. This has been fixed. The Google user-agents we provide analysis for are:
- Googlebot-Mobile: crawls pages for our mobile index
- Googlebot-Image: crawls pages for our image index
- Googlebot-MediaPartners: crawls pages to determine AdSense content (used only if you show AdSense ads on your site)
Some robots.txt files have extra characters before the start of the first rule. Some text editors place these characters in the file, but you can't see them with the editor. When the tool processed these characters, it reported a syntax error. The tool now mimics Googlebot's behavior and ignores these extra characters.
Capitalization in site URLs
When you add a site, we now convert all the letters in the domain portion of the URL to lowercase, regardless of how you entered the letters. For instance, if you enter http://www.Example.com/, we convert that to http://www.example.com/ in your account. This applies only to the domain, so for instance, if you add http://www.Example.com/MySite/, we will convert it to http://www.example.com/MySite/. If you added sites to your account using capitalized letters, you'll notice the domain portions have been converted to lowercase. We made this minor change as part of our efforts to ensure you see all available stats for your site.
Improving your site's indexing and ranking
You've submitted a Sitemap for your site. As we explain in our docs, a Sitemap can help us learn more quickly and comprehensively about the pages of your site than our other methods of crawling, but it doesn't guarantee indexing and has no impact on ranking.
What other things can you do to increase your site's indexing and ranking?
Make sure your site is full of unique, high-quality content.
Google's automated crawling, indexing, and ranking processes are focused on providing quality search results. Is your site a high-quality result for the queries you want to rank highly for? Look at your home page. Does it provide information or does it consist primarily of links? If it is mostly links, where do those links go? Do they lead visitors to good information on your site or simply to more links? Look at your site as a searcher would. If you did a search, would you be happy with your site as a result?
Does your site follow the webmaster guidelines?
Take a close look at your site and our webmaster guidelines. Remember that your site should be meant for visitors, not search engines. It's a good idea to read these guidelines and evaluate your site to make sure it meets them. If it doesn't, your site probably won't be indexed, even if you submit a Sitemap. Here are a few things to check.
Does your site use hidden text?
Hidden text is generally not visible to visitors and is meant to give web-crawling robots, such as Googlebot, different content. For instance, a site might add text in a very small font that is the same color as the page's background. Webmasters sometimes do this because they want to provide more information to the web-crawling robots, and this hidden text is often a list of keywords that the webmaster would like the site to be ranked highly for. Don't use hidden text on your site. Since Google's automated processes are focused in giving searchers high quality results, our guidelines are clear that sites should show Googlebot the same thing they show visitors so our processes can accurately evaluate them.
Does your site use keyword stuffing?
Webmasters sometimes use keyword stuffing much the same way as hidden text. They want to give Googlebot a list of terms that they want their site to rank highly for. But Google's automated processes analyze the contents of a site based on what visitors see, not on a laundry list of keywords. If you want your site to rank highly for particular keywords, make sure your site includes unique, high-quality content related to those keywords.
Does your site buy links from other sites or participate in link exchange programs that don't add value for visitors?
You want other sites to link to you. So, guidelines about links may seem confusing. You want genuine links: another site owner thinks your content is useful and relevant and links to your site. You don't want links that are intended only for Googlebot. For instance, you don't want to pay for a program that spams your link all over the Internet. You don't want to participate in link schemes that require you to link to a bunch of sites you know nothing about in exchange for links on those sites. Do you have hidden links on your site? These are links that visitors can't see and are almost always intended only for search engine web-crawling robots. Think about links in terms of visitors: are the links meant to help them find more good content or are they only meant to attract Googlebot?
Do you use search engine optimization?
If you use a search engine optimization company (SEO), you should also read through our SEO information to make sure that you aren't using one who is unfairly trying to manipulate search engine results.
If your site isn't indexed at all (you can check this by using the site: operator or by logging into your Sitemaps account, accessing the Index stats tab and then clicking the site: link) and you violate these guidelines, you can request reinclusion once you modify your site.
If your site isn't in the index, but doesn't violate these guidelines, there is no need to request reinclusion. Focus on ensuring that your site provides unique, high-quality content for users and submit a Sitemap. Creating a content-rich site is the best way to ensure your site is a high-quality result for search queries you care about and will cause others to link to you naturally.
Analyzing a robots.txt file
Earlier this week, we told you about a feature we made available through the Sitemaps program that analyzes the robots.txt file for a site. Here are more details about that feature.
What the analysis means
The Sitemaps robots.txt tool reads the robots.txt file in the same way Googlebot does. If the tool interprets a line as a syntax error, Googlebot doesn't understand that line. If the tool shows that a URL is allowed, Googlebot interprets that URL as allowed.
This tool provides results only for Google user-agents (such as Googlebot). Other bots may not interpret the robots.txt file in the same way. For instance, Googlebot supports an extended definition of the standard. It understands Allow: lines, as well as * and $. So while the tool shows lines that include these extensions as understood, remember that this applies only to Googlebot and not necessarily to other bots that may crawl your site.
Subdirectory sites
A robots.txt file is valid only when it's located in the root of a site. So, if you are looking at a site in your account that is located in a subdirectory (such as http://www.example.com/mysite/), we show you information on the robots.txt file at the root (http://www.example.com/robots.txt). You may not have access to this file, but we show it to you because the robots.txt file can impact crawling of your subdirectory site and you may want to make sure it's allowing URLs as you expect.
Testing access to directories
If you test a URL that resolves to a file (such as http://www.example.com/myfile.html), this tool can determine if the robots.txt file allows or blocks that file. If you test a URL that resolves to a directory (such as http://www.example.com/folder1/), this tool can determine if the robots.txt file allows or blocks access to that URL, but it can't tell you about access to the files inside that folder. The robots.txt file may have set restrictions on URLs inside the folder that are different than the URL of the folder itself.
Consider this robots.txt file:
User-Agent: *If you test http://www.example.com/folder1/, the tool will say that it's blocked. But if you test http://www.example.com/folder1/myfile.html, you'll see that it's not blocked even though it's located inside of folder1.
Disallow: /folder1/
User-Agent: *
Allow: /folder1/myfile.html
Syntax not understood
You might see a "syntax not understood" error for a few different reasons. The most common one is that Googlebot couldn't parse the line. However, some other potential reasons are:
- The site doesn't have a robots.txt file, but the server returns a status of 200 for pages that aren't found. If the server is configured this way, then when Googlebot requests the robots.txt file, the server returns a page. However, this page isn't actually a robots.txt file, so Googlebot can't process it.
- The robots.txt file isn't a valid robots.txt file. If Googlebot requests a robots.txt file and receives a different type of file (for instance, an HTML file), this tool won't show a syntax error for every line in the file. Rather, it shows one error for the entire file.
- The robots.txt file containes a rule that Googlebot doesn't follow. Some user-agents obey rules other than the robots.txt standard. If Googlebot encounters one of the more common additional rules, the tool lists them syntax errors.
We are working on a few known issues with the tool, including the way the tool processes capitalization and the analysis with Google user-agents other than Googlebot. We'll keep you posted as we get these issues resolved.
From the field
Curious what webmasters in the community are saying about our recent release ? Check out Matt Cutts' blog where he discusses the new robots.txt tool and answers some of your questions.
More stats and analysis of robots.txt files
Today, we released new features for Sitemaps.
robots.txt analysis
If the site has a robots.txt file, the new robots.txt tab provides Googlebot's view of that file, including when Googlebot last accessed it, the status it returns, and if it blocks access to your home page. This tab also lists any syntax errors in the file.

You can enter a list of URLs to see if the robots.txt file allows or blocks them.

You can also test changes to your robots.txt file by entering them here and then testing them against the Googlebot user-agent, other Google user agents, or the Robots Standard. This lets you experiment with changes to see how they would impact the crawl of your site, as well as make sure there are no errors in the file, before making changes to the file on your site.
If you don't have a robots.txt file, you can use this page to test a potential robots.txt file before you add it to your site.
More stats
Crawl stats now include the page on your site that had the highest PageRank, by month, for the last three months.

Page analysis now includes a list of the most common words in your site's content and in external links to your site. This gives you additional information about why your site might come up for particular search queries.

A chat with the Sitemaps team
Some members of the Sitemaps team recently took some time to answer some questions about Sitemaps. We hope we've given some insight on questions you may have wondered about.
Giving others access to Sitemaps account information
Once you add a site or Sitemap to your account and verify ownership, we show you statistics and errors about the site. Now someone else on your team also wants to view information about it. Or perhaps you set up a Sitemap for a client site and now they wants to control the Sitemap submission and view site information.
Anyone who wants to view site information can simply create a Sitemaps Account, add the site (or Sitemap), and verify ownership. The site isn't penalized in any way if it is added to multiple accounts.
Some questions you may have:
I have Sitemaps for multiple clients in my account. I don't want one client to see everything that's in my account. How do I prevent this?
The client should create their own Sitemaps account and verify site ownership. The client won't see anything that's in your account (even though a site or Sitemap may be listed in both accounts).
I've already verified site ownership and the verification file is still on my server. Does the client also have to verify site ownership?
Yes, each account holder must verify site ownership separately. We ask for a different verification file for each account.
What happens if I submit a Sitemap and then someone else in my company submits that same Sitemap using a different Sitemaps account? Do you see that as duplicate entries and penalize the site?
No, we don't penalize the site in any way. No matter the number of accounts that list the Sitemap, we see it as one Sitemap and process it accordingly.
I want the client to be able to see all the stats for this site right away. I don't want them to have to wait for stats to populate. Can I transfer my account information to the client?
Stats and errors are computed for a site, not for an account. There's no need to transfer your account information because anyone who adds a site and verifies site ownership will see all information that we available to show for that site right away.
But I don't want to list the site in my account anymore. Are you sure I can't just transfer the information to the other person's account?
If you don't want the site or Sitemap in your account any longer, you can simply delete it from your account. This won't penalize the site in any way.
More about changing domain names
Recently, someone asked me about moving from one domain to another. He had read that Google recommends using a 301 redirect to let Googlebot know about the move, but he wasn't sure if he should do that. He wondered if Googlebot would follow the 301 to the new site, see that it contained the same content as the pages already indexed from the old site, and think it was duplicate content (and therefore not index it). He wondered if a 302 redirect would be a better option.
I told him that a 301 redirect was exactly what he should do. A 302 redirect tells Googlebot that the move is temporary and that Google should continue to index the old domain. A 301 redirect tells Googlebot that the move is permanent and that Google should start indexing the new domain instead. Googlebot won't see the new site as duplicate content, but as moved content. And that's exactly what someone who is changing domains wants.
He also wondered how long it would take for the new site to show up in Google search results. He thought that a new site could take longer to index than new pages of an existing site. I told him that if he noticed that it took a while for a new site to be indexed, it was generally because it took Googlebot a while to learn about the new site. Googlebot learns about new pages to crawl by following links from other pages and from Sitemaps. If Googlebot already knows about a site, it generally finds out about new pages on that site quickly, since the site links to the new pages.
I told him that by using a 301 to redirect Googlebot from the old domain to the new one and by submitting a Sitemap for the new domain, Googlebot could much more quickly learn about the new domain than it might otherwise. He could also let other sites that link to him know about the domain change so they could update their links.
The crawling and indexing processes are completely automated, so I couldn't tell him exactly when the domain would start showing up in results. But letting Googlebot know about the site (using a 301 redirect and a Sitemap) is an important first step in that process.
You can find out more about submitting a Sitemap in our documentation and you can find out more about how to use a 301 redirect by doing a Google search for [301 redirect].
Answers to Friday questions
Today, we wanted to review a few things that we get a lot of questions about.
I tried to verify and I got a message that said "pending verification". Why?
If we can't process the verification request right away, we'll add it to a queue and process it as soon as possible. While your request is in this queue, the status will show as pending. Once we successfully process your request, your site will show as verified. If the request is unsuccessful, you'll see a status of "not verified". You can read more about reasons the request might not be successful or take a look at our documentation.
I submitted my Sitemap and it now as a status of "Timed out downloading robots.txt". I don't have a robots.txt file on my site. What happened?
Any time we access your site, we first check to see if you have a robots.txt file that restricts our access. If we get a timeout from your server when we do this check, you'll see this message. This is probably a temporary problem. Once your server is accessible again, we will be able to see that you don't have a robots.txt file, and will then access your Sitemap. If you continue to see this error, make sure that your webserver is up and responding to requests.
I submitted my sitemap at http://www.example.com/mysite/ and verified it. But now you are asking me to verify at http://www.example.com/. I can't verify at that location because I don't have access. Why are you asking me to do this?
Some stats we can only show if you verify at the root level. If you don't have access to this location, we will show you all the information we are able to (such as errors we had crawling your site). Verification doesn't impact Sitemap submission or indexing in any way, and there is no penalty if you can't verify at the root level.
I've submitted my Sitemap, verified my site, and you've downloaded my Sitemap, but many of my stats show "Data is not available at the time time". Why?
We show you stats about what we know about your site. If we haven't yet crawled and indexed much of your site, we may not have many stats to show you. As we crawl more of your site and learn more about it, you'll start to see more stats.
More language support
We've added support for four more languages and a Sitemaps Google Group for each one:
Danish
Finnish
Norwegian
Swedish
As with the other languages we support, if you already use Google in one of these languages, you should see the user interface and documentation automatically. Otherwise, you can click the Preferences link from the Google home page and choose the language from the interface list.
Happy New Year!
We hope you all had a happy holiday and New Year's celebration. Over the past few weeks the team has been doing some planning for 2006 and reviewing your feedback from 2005. We are excited about the product improvements we have in store for the new year and hope that the new features and functionality will help you all reap the rewards of Sitemaps more easily and quickly.
We appreciate your continued enthusiasm and look forward to reading more of your feedback on the Google Sitemaps Group as we embark on the new year.
Wishing you all a very prosperous 2006,
The Google Sitemaps Team
Copyright © 2005 Google Inc. All rights reserved.
Privacy Policy -
Terms of Service

Useful links |
 Site feed
Site feed{kind=link}